☑️ 인공지능
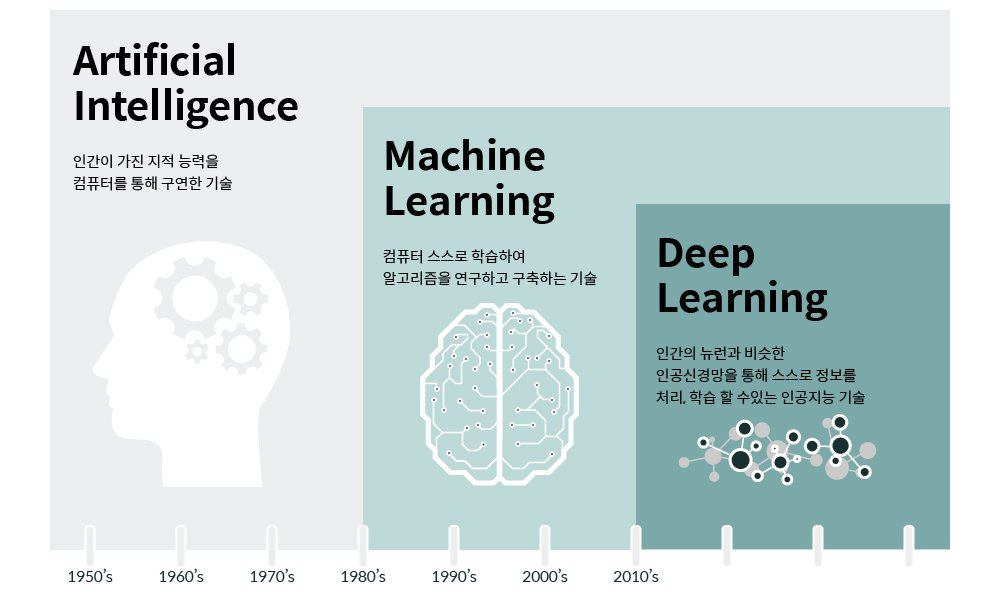
❓머신러닝과 딥러닝의 차이
머신러닝의 경우 모델을 사용하기 전 사용자가 데이터로부터 특징을 추출하는 과정이 필요할 수 있지만, 딥러닝은 데이터로부터 자동으로 특징을 추출하는 것이 가능
☑️ 머신러닝 종류
지도학습(Supervised Learning):
입력 데이터와 정답(Labeled Data)이 주어진 상황에서 모델을 학습하는 과정
① Binary Classification(이진분류): 어떤 데이터에 대해 두 가지 중 하나로 분류할 수 있는 것 ex) 스팸분류기
② Multi-Class Classification(다중분류): 어떤 데이터에 대해 여러 값 중 하나로 분류할 수 있는 것 ex) 학점예측
③ Regression(회귀): 어떤 데이터들의 특징을 토대로 연속된 값을 예측하는 것 ex) 집 값 예측
비지도학습(Unsupervised Learning):
정답 없이 입력 데이터만 주어진 상황에서 모델을 학습하는 과정
① Clustering(군집화): 비슷한 특징을 가진 개체끼리 그룹으로 묶는 것
② PCA(주성분석): 데이터를 가장 잘 설명하는 주성분을 찾아 차원을 축소하는 것
강화학습(Reinforcement Learning):
보상 시스템을 활용하여 학습하는 과정
☑️ 머신러닝 모델의 종류
선형 모델:
선형 모델은 입력 특성과 가중치의 선형 조합을 사용하여 출력을 예측하는 모델입니다. 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression) 등이 이에 속합니다. 선형 모델은 간단하고 해석이 용이하며, 특히 특성이 선형 관계일 때 잘 작동합니다.
트리 모델:
트리 모델은 의사결정 트리(Decision Tree)를 기반으로 하는 모델입니다. 의사결정 트리는 데이터를 분할해 가며 의사결정 규칙을 학습하고, 앙상블 모델로 확장된 랜덤 포레스트(Random Forest), 그래디언트 부스팅(Gradient Boosting) 등이 이에 해당합니다. 트리 모델은 비선형 관계를 잘 모델링할 수 있으며, 변수의 중요도를 제공할 수 있습니다.
딥러닝:
딥러닝은 신경망을 사용하는 모델로, 다층 신경망(Deep Neural Networks)를 포함합니다. 신경망은 입력층, 은닉층, 출력층으로 구성되어 있으며, 각 뉴런은 가중치와 활성화 함수를 사용하여 연결되어 있습니다. 딥러닝은 복잡한 비선형 관계를 모델링할 수 있으며, 특히 대규모 데이터와 복잡한 작업에서 성능이 뛰어납니다.
☑️ 머신러닝 학습 과정

- 문제 정의:
- 학습의 첫 단계로, 해결하고자 하는 문제를 명확히 정의하고 목표를 설정합니다. 예측, 분류, 군집화 등의 문제를 구체적으로 결정합니다.
- 데이터 랭글링:
- 수집한 데이터를 정제하고 준비하는 단계입니다. 결측치 처리, 이상치 제거, 데이터 스케일링 등의 작업을 수행하여 모델에 적합한 형태로 만듭니다.
- 모델링:
- 문제에 맞는 적절한 머신러닝 모델을 선택하고 설계합니다. 선형 모델, 트리 모델, 신경망 등 다양한 모델 중에서 선택합니다.
- 모델 학습 및 평가:
- 선정한 모델을 훈련 데이터에 적용하여 학습시키고, 테스트 데이터를 사용하여 모델의 성능을 평가합니다. 정확도, 정밀도, 재현율 등의 지표를 활용하여 모델 평가를 수행합니다.
- 모델 활용:
- 학습된 모델을 새로운 데이터에 적용하여 예측이나 분류를 수행합니다. 실제 문제에 모델을 적용하여 유용한 결과를 얻을 수 있습니다.
🔗 참고자료
- chatGPT
'머신러닝' 카테고리의 다른 글
| 데이터 분할 (1) | 2023.12.26 |
|---|---|
| Data Preprocessing (0) | 2023.12.12 |
| Data Wrangling (0) | 2023.12.12 |
| N122 - 중심극한정리 (0) | 2023.09.04 |
| N121- 확률 및 베이즈 정리 (0) | 2023.08.28 |